
Why Robots.txt Matters in Modern Search
For many years, robots.txt was viewed as a technical SEO file that only developers and search engine specialists worried about. Today, that perspective is changing.

Modern websites are no longer crawled exclusively by traditional search engines. Artificial intelligence platforms, large language models, answer engines, and AI-powered search systems now regularly access websites to discover, retrieve, summarize, and reference information.
This shift means website owners must think differently about crawler management.
A properly configured robots.txt file can help:
- Improve crawl efficiency
- Prevent search engines from wasting resources on low-value pages
- Guide AI systems toward important content
- Protect sensitive sections of a website
- Support traditional SEO and AI search visibility
- Control how AI crawlers interact with website content
While content quality remains essential, search engines and AI systems cannot utilize content they cannot effectively discover and access.
AI bots are crawling the web differently than traditional search engines. This episode explores how to strategically configure robots.txt to improve crawl efficiency, maintain visibility in generative AI answers, and safeguard private information. Learn the difference between crawling and indexing with Austin Code Monkey.
What Is a Robots.txt File?
A robots.txt file is a text document located in the root directory of a website. Its purpose is to provide instructions to automated crawlers regarding which sections of a website should be accessed and which sections should be avoided.
When a crawler arrives on a website, one of its first actions is often to request:
yourdomain.com/robots.txt
The crawler reviews the instructions contained within the file before continuing to explore additional URLs.
Robots.txt functions as a communication layer between website owners and automated systems.
Rather than allowing crawlers to navigate every page indiscriminately, website owners can provide guidance that improves efficiency and prioritizes valuable content.
Understanding the Difference Between Crawling and Indexing
One of the most common misconceptions in SEO involves confusing crawling with indexing.
Crawling occurs when a bot visits a page and reads its contents.
Indexing occurs when information from that page is stored and made available for search retrieval.
A robots.txt file influences crawling behavior.
It does not directly control indexing.
This distinction is important because a URL may still appear in search results if other websites link to it, even when that URL is blocked from crawling.
Website owners who want to prevent indexing should utilize appropriate indexing controls in addition to robots.txt directives.
Why Search Engines Do Not Crawl Everything
Many website owners assume search engines automatically crawl every page on a website.
In reality, search engines allocate resources carefully.
Large websites often contain thousands of URLs generated by:
- Search filters
- Product variations
- Internal search functions
- Session parameters
- Category sorting systems
- Administrative functions
Many of these pages provide little value to users.
If search engines spend excessive time crawling low-priority URLs, important content may be discovered less frequently.
This concept is commonly known as crawl efficiency.
The goal is not necessarily to reduce crawling.
The goal is to ensure crawlers spend their resources on pages that contribute to rankings, traffic, and business goals.
How Robots.txt Supports Crawl Efficiency
A well-designed robots.txt strategy helps search engines focus on the content that matters most.
Examples of commonly restricted areas include:
- Login portals
- Administrative dashboards
- Shopping carts
- Customer account pages
- Internal search results
- Temporary development environments
Restricting these sections allows crawlers to devote greater attention to:
- Service pages
- Product pages
- Educational resources
- Blog articles
- Research content
- Landing pages
The result is often more efficient crawling and better discovery of important content.
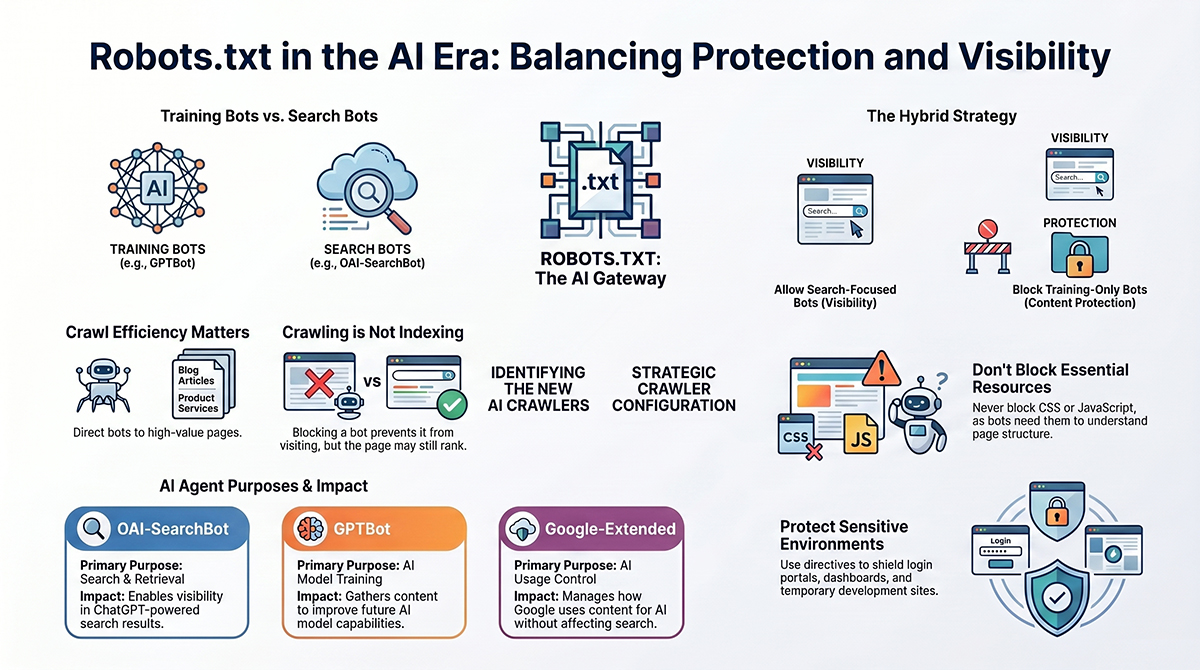
Robots.txt and AI Search Visibility
Artificial intelligence has introduced a new layer of complexity to crawler management.
Today’s AI ecosystem includes several different categories of crawlers.
Some collect information for AI model training.
Others retrieve information that may later appear in AI-generated responses.
Some build public datasets that support numerous AI systems.
Because these functions differ, businesses should evaluate their goals before deciding which crawlers to allow or block.
Organizations seeking visibility within AI-generated answers may choose a different robots.txt strategy than organizations primarily concerned with limiting content usage.
AI Crawlers Website Owners Should Know
Several AI-related crawlers are becoming increasingly important.
GPTBot
GPTBot is operated by OpenAI and is used to gather publicly available content that may contribute to AI model development and improvement.
Example:
User-agent: GPTBot
Allow: /
OAI-SearchBot
OAI-SearchBot focuses on retrieval and search-related functions.
Websites seeking visibility within AI-powered search experiences may choose to allow this crawler.
Example:
User-agent: OAI-SearchBot
Allow: /
ClaudeBot
ClaudeBot is operated by Anthropic and is associated with content collection activities.
Example:
User-agent: ClaudeBot
Allow: /
Claude-SearchBot
Claude-SearchBot is designed to support retrieval and search-related experiences.
Example:
User-agent: Claude-SearchBot
Allow: /
Google-Extended
Google-Extended provides website owners with controls related to certain AI-related uses of content while maintaining visibility within traditional Google Search.
Example:
User-agent: Google-Extended
Allow: /
CCBot
CCBot is operated by Common Crawl and contributes data used by numerous open-source AI projects and research initiatives.
Example:
User-agent: CCBot
Allow: /
Strategic AI Crawler Configurations
Not every organization has the same goals.
Some businesses prioritize maximum AI visibility.
Others prioritize content protection.
A balanced approach often involves allowing retrieval-focused crawlers while restricting crawlers primarily associated with training activities.
Example:
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
This strategy attempts to preserve opportunities for AI search visibility while limiting certain forms of content collection.
Common Robots.txt Mistakes That Harm Visibility
Many SEO issues originate from simple technical mistakes.
One of the most damaging errors is unintentionally blocking an entire website.
A single directive can prevent compliant crawlers from accessing all content.
Another common problem involves blocking resources required for rendering, including CSS and JavaScript files.
Modern search engines rely on these resources to understand page structure, functionality, and user experience.
Website migrations can also introduce problems when development robots.txt rules accidentally remain active after launch.
Regular audits help identify these issues before they affect visibility.
Should Every Website Block AI Crawlers?
Not necessarily.
Businesses should evaluate the trade-offs carefully.
Blocking AI crawlers may reduce certain forms of content usage, but it may also reduce opportunities for inclusion in AI-generated responses.
Organizations investing heavily in AI Search Optimization often choose a more selective strategy rather than implementing blanket restrictions.
The decision ultimately depends on business objectives, content strategy, and visibility goals.
Robots.txt Is No Longer Just an SEO File
The role of robots.txt has expanded significantly.
What was once primarily a search engine management tool now influences how websites interact with AI systems, retrieval engines, and emerging search technologies.
As search continues evolving toward conversational interfaces and AI-generated answers, crawler management is becoming an increasingly important component of digital visibility.
Businesses that understand how to control crawler access, improve crawl efficiency, and strategically manage AI bots will be better positioned to compete in both traditional search results and the next generation of AI-powered discovery platforms.
Final Thoughts
Robots.txt remains one of the smallest files on a website, yet it can have a substantial impact on online visibility.
Whether your goal is improving SEO performance, supporting AI search visibility, protecting content, or optimizing crawl efficiency, robots.txt serves as a foundational component of technical website management.
As AI search continues to evolve, organizations that actively manage crawler access will have greater control over how their content is discovered, processed, and presented across the digital ecosystem.
Not Sure If Your Robots.txt File Is Helping or Hurting Your Website?
Most business owners never look at their robots.txt file until rankings drop, pages disappear from search results, or AI platforms stop surfacing their content.
Don’t wait for a visibility problem to discover a technical SEO issue.
Austin Code Monkey specializes in Technical SEO, Local SEO, AI Search Optimization, website audits, and digital marketing strategies designed to help businesses increase their online visibility.
We’ll analyze your robots.txt file, crawl directives, indexing setup, sitemap configuration, and AI crawler accessibility to ensure search engines and AI platforms can properly discover your most valuable content.

Call 737-932-7532 or visit austincodemonkey.com to schedule your SEO and AI Search Optimization review today and learn how to position your business for the future of search.
Because when your local search game is on point, your business doesn’t just survive, it dominates.
Austin Code Monkey
Phone: (737) 932-7532
Hours: Monday – Friday, 10:00 AM – 10:00 PM
Website: https://austincodemonkey.com/
Get Started Today:
- Call (737) 932-7532 for a free consultation
- Schedule your complimentary SEO audit
- Discover how SEO and AI Search Optimization can transform your business
Don’t let your competitors dominate your business in search queries. Partner with Austin’s leading local SEO experts and ensure your business appears when and where your customers are searching. Contact Austin Code Monkey today and take the first step toward complete digital dominance in the Austin market.
